
この記事は、Intel Tech.Decoded で公開されている「1.47x Speed-Up for Popular Machine Learning Library」(https://techdecoded.intel.io/resources/1-47x-speed-up-for-popular-machine-learning-library/#gs.7krvs3) の日本語参考訳です。
Yandex がインテル® VTune™ プロファイラーのホットスポット解析を使用して CatBoost のパフォーマンスを最適化
Yandex (英語) は、ロシアの主要インターネット/クラウド企業であり、世界中のマシンラーニングや人工知能 (AI) に大きく貢献しています。Yandex の CatBoost (英語) は、決定木の勾配ブースティング用のハイパフォーマンスなオープンソース・ライブラリーです。
CatBoost のパフォーマンス・ボトルネックを特定するため、Yandex はインテルのソフトウェア開発チームと協力して、インテル® oneAPI ベース・ツールキットの主要デバッグツールであるインテル® VTune™ プロファイラーを使用して、いくつかのデータセットで CatBoost フレームワークのホットスポット解析を行いました。ボトルネックを特定することで、Yandex はインテル・プラットフォームで CatBoost のパフォーマンスを 1.47 倍向上できました。
効率良いマシンラーニング・モデル
Yandex の研究者は、マシンラーニング・モデルのトレーニングと予測を行うため CatBoost を開発しました。Yandex をはじめ、CERN や Cloudflare などの著名な企業が CatBoost の機能を利用しています。CatBoost のデフォルトのパラメーターを使用することで、開発者はパラメーターのチューニングにかかる時間を排除できます。トレーニング結果を向上するため、CatBoost では、データを前処理したり、手間をかけて数値化する代わりに、数値以外の係数を使用できます。ユーザーは、勾配ブースティング・アルゴリズムの高速実装によりモデルをトレーニングできます。モデル適用機能は、ユーザーがトレーニングしたモデルを、レイテンシーが重要なタスクに対しても、素早く効率良く適用可能です。
CatBoost の価値を最大限に引き出すため、Yandex は CPU ベアメタルやクラウド上でのパフォーマンスを最適化する必要がありました。最高のパフォーマンスを達成するため、Yandex はインテル® VTune™ プロファイラーを使用しました。
CatBoost のパフォーマンスを最大化
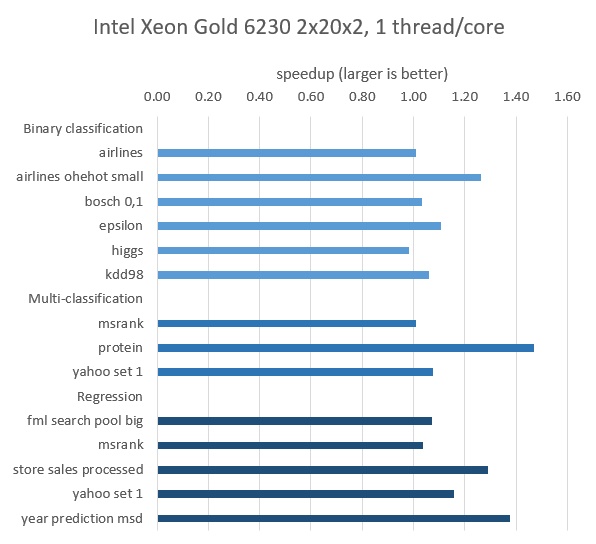
Yandex は、インテル® Xeon® プロセッサーとインテル® Xeon® スケーラブル・プロセッサーを含むインテルの CPU プラットフォームで、いくつかのオープンソースのデータセットを使用して CatBoost のパフォーマンスを評価しました (図 1 と 2)。
インテル® VTune™ プロファイラーはコードを解析して、主要なプロファイル・データを収集して、計算やスレッドからメモリーやストレージに至るまで、開発者が最も効果的な最適化に注目できるように GUI に分かりやすく表示します。
Yandex は、図 1 と 図 2 に示すデータセットのトレーニング時間を検証し、インテル® VTune™ プロファイラーの推奨に従ってこれらのモデルを最適化することでスピードアップを達成しました。
インテル® VTune™ プロファイラーのホットスポット解析は、フォルス・シェアリングや非効率なメモリーアクセスにつながるアトミック同期などを示しました。ボトルネックを特定することで、Yandex は CatBoost のパフォーマンスを 1.47 倍向上できました。
ボトルネックの特定とパフォーマンスの向上
インテルと Yandex の協力により、データ・サイエンティストはインテル・プラットフォームにおいて、より複雑なモデルとデータセットをより高速にトレーニングできるようになり、開発者コミュニティーでは CatBoost マシンラーニング・ライブラリーの人気が高まっています。CatBoost のパフォーマンス結果は、世界中のデータ・サイエンティストが計算リソースを効率良く利用し、クラウドリソースを節約するのに役立つでしょう。
インテル・ソフトウェア・ツールは、Yandex のソフトウェア開発者が世界中のデータ・サイエンティストに価値を提供するのを支援しました。
関連情報
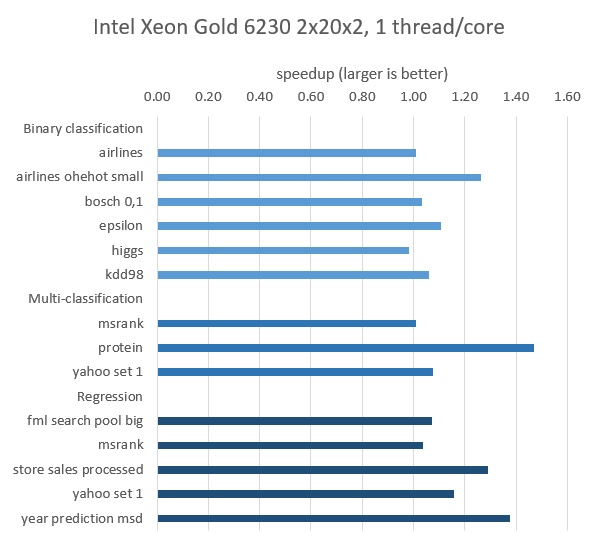
図 1. インテル® Xeon® Gold 6230 プロセッサー、40 物理コア、物理コアごとに 1 スレッド上でのトレーニング結果
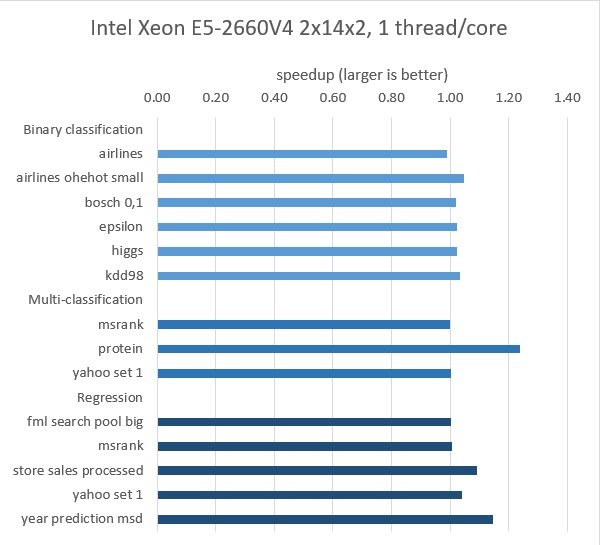
図 2. インテル® Xeon® プロセッサー E5-2660 V4、2 ソケット、ソケットごとに 14 コア、コアごとに 2 HT、物理コアごとに 1 スレッド上でのトレーニング結果
製品とパフォーマンス情報
1実際の性能は利用法、構成、その他の要因によって異なります。詳細は、www.Intel.com/PerformanceIndex (英語) を参照してください。
